✨你好,我是筱可,欢迎来到「筱可AI研习社」!
🚀 标签关键词:| AI实战派开发者 | 技术成长陪伴者 | RAG前沿探索者 |
今天咱们就直接进入正题,聊聊基于Paddle平台构建的版面检测实战。
本次的主题是:
基于paddle平台构建的版面检测实战
话不多说,直接开整!!!
通过本文你将收获
🛠️ 学会怎么用PaddleDetection模型来检测论文版面内容。
🔥 弄明白PaddleDetection模型是怎么实现版面分析的。
🚀 拿到PaddleDetection推理模型,还有我从Paddle部分整理出来的推理源码。
下篇文章预告:
接下来会进一步拆解封装版面检测部分的代码,封装出一个更可控的版面检测封装类。
tips: 现在官方的代码有点乱,直接用他们的代码不太现实。后面我们会把源代码拆开,重新封装,弄出一个属于咱们自己的推理函数或者类。为啥不用Paddle提供的库呢?我自己跑的时候没跑通,依赖太复杂了,教程好多也过期了,很难用。而且要是不动源码,连识别到的内容都拿不到,所以这事儿必须得做。
目录
🚁前言
上一次,我们写了《大模型应用极简开发快速入门》,里面提到pdf文件可以用pymupdf(fitz)来提取内容。这个工具挺厉害的,能提取文本、表格、图片,还有元数据这些。不过也有缺点,比如不能直接提取成markdown格式。要是你想弄成markdown格式,就算基于pymupdf来弄,也得费不少功夫。好在fitz官方基于pymupdf封装了一个pymupdf4llm库,用两行简单代码就能把pdf文件转成markdown格式的内容。但这个库也有缺陷,后面我们再详细说。
🔐一、说说pymupdf4llm与fitz的优缺点
pymupdf4llm的问题
fitz的不足
fitz也解决不了上面说的问题。因为pymupdf是基于fitz做的,我从2023年底就开始用pymupdf折腾转markdown格式了。不管是把文本、图片、表格分别提取再整合,还是先转成html再转markdown,虽然有点进展,但效果还是不太好。之前看到RAGflow基于飞浆平台的做法,我就非常喜欢,但是代码耦合比较深,从他们那边入手,还不如我去飞浆找代码,他们好像优化了模型,可能微调了吧。
它们的优点
速度快:底层是C语言,在python生态里速度表现很不错。
适合简单排版:要是文档格式、排版不复杂,基本可以直接用fitz或者pumupdf4llm,我测试过的工具里,它们是最好用的。
内容提取较完整:除了图片内容不会单独ocr,其他内容提取得还算完整。
再强调一下,它们都处理不了数学公式。
🎨二、认识PaddleDetection
(下面是官网说的,我觉得说得挺好,就直接拿来用了)
版面分析就是把图片形式的文档进行区域划分,找到里面的关键区域,像文字、标题、表格、图片这些。版面分析算法是基于PaddleDetection的轻量模型PP-PicoDet开发的,有英文、中文、表格版面分析3类模型。英文模型能检测Text、Title、Tale、Figure、List这5类区域;中文模型能检测Text、Title、Figure、Figure caption、Table、Table caption、Header、Footer、Reference、Equation这10类区域;表格版面分析模型就只支持检测Table区域。版面分析效果如下图所示: 
⚙️三、PaddleDetection的优缺点
缺点
优点
📄四、运行PaddleDetection的步骤
用我提供的代码压缩包,然后按下面的说明来操作
你可以参考的资料(虽然时效性不太好,但能参考一下)
官方教程文档-版面分析-PaddleOCR 文档: https://paddlepaddle.github.io/PaddleOCR/main/ppstructure/model_train/train_layout.html
操作步骤
进入飞浆版面分析目录
cd paddle_layout
安装依赖
pip install -r requirements.txt
运行命令
python infer.py --model_dir=model/picodet_lcnet_x1_0_fgd_layout_infer/ --image_file=images/layout.jpg --device=CPU
你将会看到如下的现象:
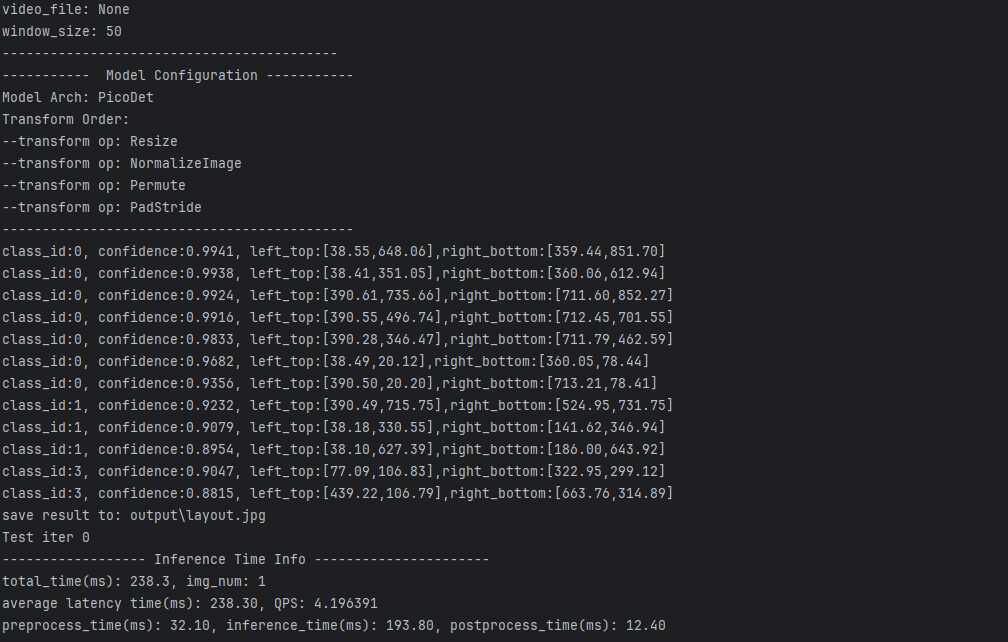
到了这里,你已经成功地运行出来了基于飞浆平台地版面检测识别模型,你如果不出意外,你的当前目录会输出一个output,类似我这里的样子output下面会有一个检测结果。
 不出意外的话,你可以得到一个这样的图片:
不出意外的话,你可以得到一个这样的图片:
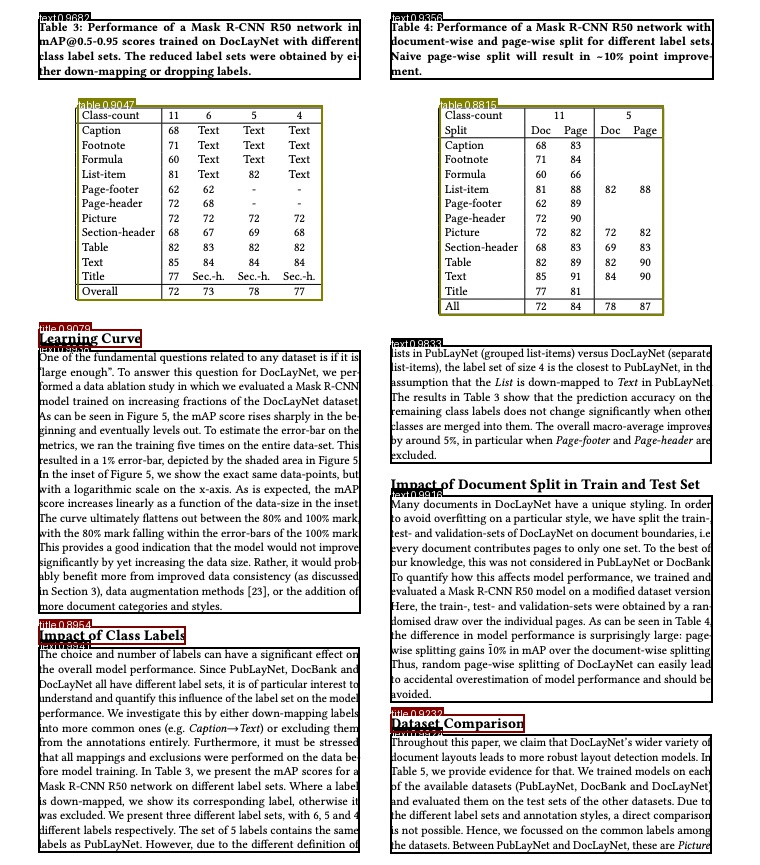
恭喜你,距离一名优秀的PDF提取工程师又进了一步,加油,共勉吧!
(悄悄凑个字数吧)
欣见您在成为卓越PDF解析专家的征途上再攀新高!愿我们以匠人之心共砺技艺,以开拓之志同赴技术深水区。每一次数据结构的精准拆解,都是向专业巅峰迈出的坚实步伐,期待与您共同探索文档解析的无限可能!
总结
技术全景图
学习汇总
🔒 pymupdf4llm与fitz在提取PDF内容时的优势和不足。
🎛️ PaddleDetection模型的原理和应用场景。
💬 运行PaddleDetection的具体操作流程。
📑 PaddleDetection在版面分析里的价值和用法。
动手挑战
在本地成功运行这次提供的PaddleDetection代码,对pdf或者图片做版面分析。
要是本地有GPU\NPU,切换成GPU\NPU运行试试,把运行结果和体验在留言区告诉我,谢谢!
内容地图
下期预告:
《pdf提取逆天神器版面检测分析+版面识别,通过飞浆系列OCR提升pdf识别效果(2)》
互动问题
你处理PDF的时候遇到最大的挑战是什么?
这次的代码你跑起来了吗?过程中遇到什么问题?
看了这篇文章,你有什么感受?
欢迎在留言区分享你的想法,每条留言我都会认真看!你的反馈就是我创作的最大动力 ❤️
一个人可以走得很快,一群人可以走得很远!
——筱可 (嘿!这句话是我写的哦!)
欢迎加入我们!
立即行动
点赞+喜欢+关注+分享给有需要的伙伴。
给公众号加星号。
在本地运行示例代码,体验完整流程。
(恭喜!您已获得百度飞浆版面检测大礼包,请在公众号回复「版面检测」领取)
行动召唤
"与其等着AI改变世界,不如自己参与变革!在这儿,让AI成为你弯道超车的秘密武器。"
信息交流
入群交流 & 资料领取
⛄入群方式
☯资料领取