相信大家对于几个库的差异与使用场景有了一定的认识,本文将继续介绍另外两种操作Excel的Python库---xlrd与xlwt。看看这两者搭配起来如何玩出火花!
和以前文章一样,有请老朋友openpyxl登场来进行对比
openyxl:可以对xlsx、xlsm文件进行读、写操作,主要对Excel2007年之后的版本(.xlsx)xlrd:可以对xlsx、xls、xlsm文件进行读操作且效率高xlwt:主要对xls文件进行创建写操作且效率高,但是不能写xlsx文件以及不能改写已经存在的xls文件
通过对比,可以看到在效率上而言,xlrd&xlwt比openyxl要高效得多。而写入数据方面上而言,openyxl又比较贴近我们的日常所需,所以两种方式来处理Excel各有千秋。
title:**本库回忆**
title:**本库重点**
- 行列的索引方式都是零索引
- xlwt是不能够为已有的xls文件写入数据的
title:**本库犯错**
- `xlrt`不能直接打开一个表作为`workbook`对象,要先使用`copy`方法对`xlrd`使用`open_workbook`方法打开的对象进行`copy`,然后对这个对象在使用`workbook`方法后才能进行下一步的数据写入或者是表格保存
- 对于过老版本的Excel xls 格式会遭遇BIFF8/BIFF6二进制编码格式兼容问题,具体案例见[链接](https://chatgpt.com/share/68143239-c788-8011-a935-c034e0d07b31),所以哪怕他对xls有支持,但是兼容性不佳
- Excel 表方案采纳建议是`xlwings>openpyxl>xlrd&xlutils>xlrd&xlwd`
1. 简介
xlrd是用来从Excel中读写数据的,但我们通常只用它进行读操作,写操作会相对于专门写入的模块麻烦一些。其实,后面的rd可以看出是reader的缩写。
类比于xlrd的reader,那么xlwt就相对于writer,而且很纯正的一点就是它只能对Excel进行写操作。xlwt和xlrd不光名字像,连很多函数和操作格式也是完全相同。下面让我们慢慢介绍。
2. 安装与使用
安装很简单,直接在命令行或者终端中使用pip安装
pip install Xlrd
pip install xlwt
而使用xlrd&xlwt操作Excel的大致过程如下图所示
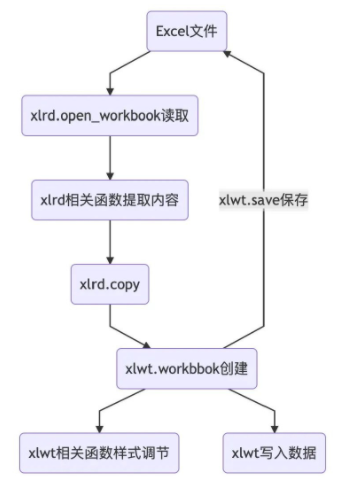
3. 方法介绍
3. 方法介绍
3.1. Workbook 对象
xlrd (读取)
xlrd.open_workbook(filename): 打开一个 Excel 文件,返回一个 Workbook 对象。
workbook.sheet_names(): 返回工作簿中所有工作表的名称列表。workbook.sheets(): 返回工作簿中所有 Sheet 对象的列表。workbook.sheet_by_index(sheet_index): 通过索引获取工作表。
sheet_index: 工作表的索引,从 0 开始。
workbook.sheet_by_name(sheet_name): 通过名称获取工作表。
xlwt (写入)
xlwt.Workbook(): 创建一个新的工作簿对象。workbook.add_sheet(sheetname, cell_overwrite_ok=False): 添加一个新的工作表到工作簿中。
sheetname: 工作表的名称。cell_overwrite_ok: 可选参数,默认为 False。如果设置为 True,则允许覆盖已写入的单元格。
workbook.save(filename): 保存工作簿到指定的 Excel 文件。
filename: 保存的文件名,必须是 .xls 格式。
3.2. Sheet 对象
xlrd (读取)
sheet.nrows: 返回工作表的行数。sheet.ncols: 返回工作表的列数。sheet.row_values(row_index, start_colx=0, end_colx=None): 返回指定行的所有单元格值的列表。
row_index: 行索引,从 0 开始。start_colx: 可选参数,起始列索引,默认为 0。end_colx: 可选参数,结束列索引,默认为 None,表示到行尾。
sheet.col_values(col_index, start_rowx=0, end_rowx=None): 返回指定列的所有单元格值的列表。
col_index: 列索引,从 0 开始。start_rowx: 可选参数,起始行索引,默认为 0。end_rowx: 可选参数,结束行索引,默认为 None,表示到列尾。
sheet.cell(row_index, col_index): 返回指定单元格的 Cell 对象。
row_index: 行索引,从 0 开始。col_index: 列索引,从 0 开始。
xlwt (写入)
sheet.write(row, col, label, style=XFStyle()): 将数据写入到指定的单元格。
row: 行索引,从 0 开始。col: 列索引,从 0 开始。label: 要写入的数据。style: 可选参数,单元格样式,默认为默认样式。
3.3. Cell 对象
xlrd (读取)
cell.value: 返回单元格的值。cell.ctype: 返回单元格的数据类型。常见类型包括:
xlrd.XL_CELL_EMPTY: 空单元格xlrd.XL_CELL_TEXT: 文本xlrd.XL_CELL_NUMBER: 数字xlrd.XL_CELL_DATE: 日期xlrd.XL_CELL_BOOLEAN: 布尔值xlrd.XL_CELL_ERROR: 错误
xlwt (写入)
xlwt 本身不直接操作 Cell 对象。单元格的写入是通过 sheet.write() 方法实现的。如果需要更精细地控制单元格的样式,可以使用 xlwt.XFStyle() 创建样式对象,并将其传递给 sheet.write() 方法。
4. xlrd基本用法
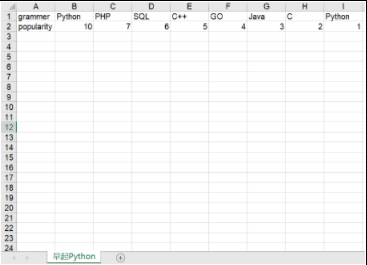
现在我们讲解xlrd操作Excel部分常用操作,先准备一份Excel文件,大致如下图:
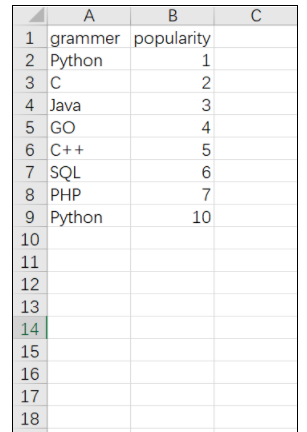
用xlrd进行读取比较方便,流程和平常手动操作Excel一样,打开工作簿(Workbook),选择工作表(sheets),然后操作单元格(cell)。接下来先介绍一下基本操作在举个例子。
4.1 打开Excel文件
import xlrd
df = xlrd.open_workbook(name)
先导入模块而后使用open_workbook()函数来读取指定的一个工作簿对象。这里的参数name是Excel文件的名字,一般使用的是相对路径的名字,结果如下
4.2 查看工作簿中所有sheet
df.sheet_names()
我们读取上述文件,便可以得到以列表形式嵌字符串的值。

4.3 选择某一个工作表
table=df.sheets()[0] #列表是从0开始计数
table=df.sheet_by_index(0)
table=df.sheet_by_name('name')
第一行代码是获取第一个工作表的意思,写法是根据内置的列表格式来选取的。
第二行代码顾名思义是通过索引获取第一个工作表,这里的索引与pandas中DataFrame的index索引类似,只不过对象换成了工作表。
第三行代码是通过表的名称选择工作表,如果工作表是有自己的名字的,那么这个读取方式是最方便的。
打印table,可以得到类似下图的结果

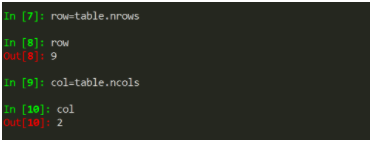
4.4 获取表格的行数和列数
注意,这里不需要在函数后面加小括号,否则你可能debug时都头痛于错在哪。
row=table.nrows
col=table.ncols
打印row和col,可以发现是和我们的原表格一样的行列数。
4.5 获取整行和整列的值
这里需要注意两个参数:num1和num2
table.row_values(num1)
table.column_values(num2)
num1在row_values()中,指的是选取的行数时多少,例如我们选取第一行所有字段名称数据,那么这个num1就是0。
同理,column_values()的参数就是第几列的意思。
它出来的值是一个列表的形式。调用第一行代码,可以得到如下结果。


<center><b></b></center>
<center><b>图:实际获取表格中某整行变量后相关变量存储数据详情</b></center>
# 读取行数据
row_data = temp_storage_workbook.sheet_by_index(0).row_values(row_index)#
headers = row_data.row_values(0)
header_index = {name: idx for idx, name in enumerate(headers)}
# 获取行数据中的公司名称
company_name = row_data[header_index["公司"]]
# 获取行数据中的金额
amount = row_data[header_index["公司"]]
# 打开主表公司worksheet,追加金额数据
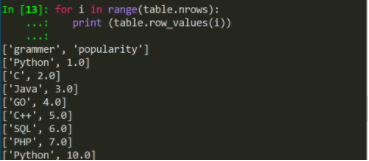
4.6 通过循环读取表格的所有行
在第五步我们实现了读取单行单列的数据,那么我们就用循环来将所有行打印出来。
for i in range(table.nrows):
print (table.row_values(i))
效果如下
4.7 获取单元格的值
代码很简单,有点像VBA
cell1=table.row(0)[0].value
cell1=table.cell(0,0).value
cell1=table.col(0)[0].value
第一行获取单元格值的方式是通过调取指定行数据进行筛选。
第二行是以二维的形式获取,即(第i行,第j列)形式。
第三行与第一行类似是通过列索引调用。

# 获取表头数据
headers = row_data.row_values(0)
# 读取行数据
row_data = temp_storage_workbook.sheet_by_index(0).row_values(row_index)#
# 创建一个字典,用于存储列索引和列名的对应关系
header_index = {name: idx for idx, name in enumerate(headers)}
# 获取行中公司列单元中公司名数据
company_name = row_data[header_index["公司"]]
# 获取行中金额列单元中金额数据
amount = row_data[header_index["金额"]]
# 打开主表公司worksheet,追加金额数据
<center><b>码:通过列名访问每一行对应列数据</b></center>
4.8 例子
最后来举一个完整的例子
df=xlrd.open_workbook('data.xlsx')
table=df.sheet_by_name('早起Python')
data_list=[]
data_list.append(table.row_values(1))
for i in data_list:
print(i)
打出来的结果
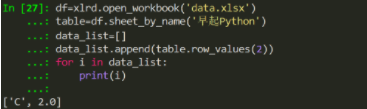
这里我们的目的是选取上述讲解过的语法,将第三行所有数据放到data_list列表中并用for循环将它打印出来。
5. xlwt基本用法
5.1 新建一个Excel文件
title:**本节犯错**
- xlwt不支持从已有的xls文件中载入对象,需要搭配xlutils库的copy方法,复制xlrd中打开的Excel对象后才能操作
创建新文件直接使用.Workbook()即可,而不是在copy后的对象上调用workbook()方法
import xlwt
df2 = xlwt.Workbook()
5.2 新建一个工作表
这里的name是工作表的名称
table2=df2.add_sheet('name')
5.3 写入数据到指定单元格
这里有三个参数,前两个参数对应(第i行,第j列),代表的是单元格的位置。第三个参数是要写的值(可以是字符串、数字)
table2.write(0,0,'Python')
需要注意的是,如果是对同一个单元格重复操作,会让Python报错(多次输入错误),所以如果想要取消这个功能,则添加这个参数在新建工作表的代码里面。
table2=df2.add_sheet('name',cell_overwrite_ok=True)
5.4 保存文件
上面提示过,xlwt仅支持.xls的文件格式输出,常用的xlsx是不行的。这也是这个模块的一种缺陷。
df2.save('data2.xls')
5.5 改变样式
调整样式也是可以的,先看几行代码
style=xlwt.XFStyle()
font=xlwt.Font()
font.name='name Times New Roman'
font.bold=True
style.font=font
sheet.write(0,1,'Python',style)
第一行代码是初始化样式,可以认为是一个类似于父类的东西。
第二行代码是为样式创建字体
第三行代码是指定字体的名字,这里用到的是name Times New Roman这个类型。
第四行代码是字体加粗,以布尔值的形式的设定。
第五行代码是将font设定为style的字体
第六行代码是写入文件单元格时怎么运用这个格式。
5.6 例子:
最后,我们结合两个模块进行读写操作。
我们的目标是将已经准备好的data文件进行读取,并将其内容进行倒序排序,最终以转置形式输出。先思考一下如何使用代码实现
“对于xlwt写入部分,先创建一个早起Python的工作表。并将提取的数据列表data_list1用列表的倒叙来排序。最后用pop()函数把两个字段名称(grammer 和 popularity)放在首位。最后结合我们写入部分讲解的内容进行保存。
在xlrd读取部分我们稍有不同的是,我们的for循环用在了提取所有数据这一步骤,而不再是循环输出列表值。
”
所以完整代码如下
import xlrd
df=xlrd.open_workbook('data.xlsx')
table=df.sheet_by_name('早起Python')
data_list=[]
for i in range(table.nrows):
data_list.append(table.row_values(i))
data_list1 = []
data_list1 = data_list[::-1]
item = data_list1.pop(-1)
data_list1.insert(0,item)
import xlwt
df2 = xlwt.Workbook()
table2=df2.add_sheet('早起Python')
for i in range(2):
for j in range(9):
table2.write(i,j,data_list1[j][i])
df2.save('data2.xls')
至此我们就将xlrd与xlwt的常用操作都盘点了一遍,如果想要了解的透彻一点的话,早起还是建议按照文中介绍的顺序自己动手敲一遍代码来体会!
最后也希望大家能够体会不同库之间的异同与使用场景,当然Python操作Excel的库并不止这五个(openpyxl、xlswriter、xlwings、xlrd、xlwt),我会在全部介绍一遍后为大家送上总结!