零基础开胃菜 - C语言中文网 (biancheng.net)
3. 变量
5. 逻辑
6. 数组
6.1 简介
在《C语言数据输出大汇总以及轻量进阶》一节中我们举了一个例子,是输出一个 4×4 的整数矩阵,代码如下:
1. #include <stdio.h>
2. #include <stdlib.h>
3. int main()
4. {
5. int a1=20, a2=345, a3=700, a4=22;
6. int b1=56720, b2=9999, b3=20098, b4=2;
7. int c1=233, c2=205, c3=1, c4=6666;
8. int d1=34, d2=0, d3=23, d4=23006783;
10. printf("%-9d %-9d %-9d %-9d\n", a1, a2, a3, a4);
11. printf("%-9d %-9d %-9d %-9d\n", b1, b2, b3, b4);
12. printf("%-9d %-9d %-9d %-9d\n", c1, c2, c3, c4);
13. printf("%-9d %-9d %-9d %-9d\n", d1, d2, d3, d4);
15. system("pause");
16. return 0;
17. }
运行结果:
20 345 700 22
56720 9999 20098 2
233 205 1 6666
34 0 23 23006783
矩阵共有 16 个整数,我们为每个整数定义了一个变量,也就是 16 个变量。那么,为了减少变量的数量,让开发更有效率,能不能为多个数据定义一个变量呢?比如,把每一行的整数放在一个变量里面,或者把 16 个整数全部都放在一个变量里面。答案当然是肯定的,办法就是使用数组(Array)。
总结:数组就是多个同一变量类型构成的有序变量,常见的字符串变量全称应该叫做字符串数组变量。其实质是由多个单字符变量组成的一个排列,在内存空间上看:就是把单个字符变量(元素)地址从左到右依次排列在内存空间上,并且给这个字符串数组(集合)分配了一个内存地址,这样你既能够访问大的整体也能够访问这个整体中的元素了。之所以要访问,那是因为访问是读取和修改值的前提。
6.2 概念和定义
我们知道,要想把数据放入内存,必须先要分配内存空间。放入4个整数,就得分配4个int类型的内存空间:
int a[4];
这样,就在内存中分配了4个int类型的内存空间,共 4×4=16 个字节,并为它们起了一个名字,叫a。
我们把这样的一组数据的集合称为数组(Array),它所包含的每一个数据叫做数组元素(Element),所包含的数据的个数称为数组长度(Length),例如int a[4];就定义了一个长度为4的整型数组,名字是a。
数组中的每个元素都有一个序号,这个序号从0开始,而不是从我们熟悉的1开始,称为下标(Index)。使用数组元素时,指明下标即可,形式为:
arrayName[index]
arrayName 为数组名称,index 为下标。例如,a[0] 表示第0个元素,a[3] 表示第3个元素。
接下来我们就把第一行的4个整数放入数组:
a[0]=20;
a[1]=345;
a[2]=700;
a[3]=22;
这里的0、1、2、3就是数组下标,a[0]、a[1]、a[2]、a[3] 就是数组元素。
在学习过程中,我们经常会使用循环结构将数据放入数组中(也就是为数组元素逐个赋值),然后再使用循环结构输出(也就是依次读取数组元素的值),下面我们就来演示一下如何将 110 这十个数字放入数组中:
1. #include <stdio.h>
2. int main(){
3. int nums[10];
4. int i;
6. //将1~10放入数组中
7. for(i=0; i<10; i++){
8. nums[i] = (i+1);
9. }
11. //依次输出数组元素
12. for(i=0; i<10; i++){
13. printf("%d ", nums[i]);
14. }
16. return 0;
17. }
运行结果:
1 2 3 4 5 6 7 8 9 10
变量 i 既是数组下标,也是循环条件;将数组下标作为循环条件,达到最后一个元素时就结束循环。数组 nums 的最大下标是 9,也就是不能超过 10,所以我们规定循环的条件是 i<10,一旦 i 达到 10 就得结束循环。
更改上面的代码,让用户输入 10 个数字并放入数组中:
1. #include <stdio.h>
2. int main(){
3. int nums[10];
4. int i;
6. //从控制台读取用户输入
7. for(i=0; i<10; i++){
8. scanf("%d", &nums[i]); //注意取地址符 &,不要遗忘哦
9. }
11. //依次输出数组元素
12. for(i=0; i<10; i++){
13. printf("%d ", nums[i]);
14. }
16. return 0;
17. }
运行结果:
22 18 928 5 4 82 30 10 666 888↙
22 18 928 5 4 82 30 10 666 888
第 8 行代码中,scanf() 读取数据时需要一个地址(地址用来指明数据的存储位置),而 nums 表示一个具体的数组元素,所以我们要在前边加 & 来获取地址。
最后我们来总结一下数组的定义方式:
dataType arrayName[length];
dataType 为数据类型,arrayName 为数组名称,length 为数组长度。例如:
1. float m[12]; //定义一个长度为 12 的浮点型数组
2. char ch[9]; //定义一个长度为 9 的字符型数组
需要注意的是:
1) 数组中每个元素的数据类型必须相同,对于int a[4];,每个元素都必须为 int。
2) 数组长度 length 最好是整数或者常量表达式,例如 10、204 等,这样在所有编译器下都能运行通过;如果 length 中包含了变量,例如 n、4m 等,在某些编译器下就会报错,我们将在《C语言变长数组:使用变量指明数组的长度》一节专门讨论这点。
3) 访问数组元素时,下标的取值范围为 0 ≤ index < length,过大或过小都会越界,导致数组溢出,发生不可预测的情况,我们将在《C语言数组的越界和溢出》一节重点讨论,请大家务必要引起注意。
6.3 特性
6.3.1 内存连续
数组是一个整体,它的内存是连续的;也就是说,数组元素之间是相互挨着的,彼此之间没有一点点缝隙。下图演示了int a[4];在内存中的存储情形:

「数组内存是连续的」这一点很重要,所以我使用了一个大标题来强调。连续的内存为指针操作(通过指针来访问数组元素)和内存处理(整块内存的复制、写入等)提供了便利,这使得数组可以作为缓存(临时存储数据的一块内存)使用。大家暂时可能不理解这句话是什么意思,等后边学了指针和内存自然就明白了。
6.4 操作
6.4.1 定义
定义一个数组首先得明确一件事,你想要一个什么类型的数组,因为数组是连续元素构成的集合,考虑组建这个大的集合首先我们要考虑小的元素是什么样子的。其次我们再来考虑要多少个元素、这些元素按照什么样的方式排布(一维、二维...)
例:int a[4]中的int表示每一个小元素(数组元素)的类型,这些小元素决定了这个大集合(数组)的类型,[4]表示这个大集合(数组)有四个元素(数组元素)。
6.4.2 赋值
上面的代码是先定义数组再给数组赋值,我们也可以在定义数组的同时赋值,例如:
int a[4] = {20, 345, 700, 22};
数组元素的值由{ }包围,各个值之间以,分隔。
对于数组的初始化需要注意以下几点:
1) 可以只给部分元素赋值。当{ }中值的个数少于元素个数时,只给前面部分元素赋值。例如:
int a[10]={12, 19, 22 , 993, 344};
表示只给 a[0]a[4] 5个元素赋值,而后面 5 个元素自动初始化为 0。
当赋值的元素少于数组总体元素的时候,剩余的元素自动初始化为 0:
- 对于short、int、long,就是整数 0;
- 对于char,就是字符 '\0';
- 对于float、double,就是小数 0.0。
我们可以通过下面的形式将数组的所有元素初始化为 0:
int nums[10] = {0};
char str[10] = {0};
float scores[10] = {0.0};
由于剩余的元素会自动初始化为 0,所以只需要给第 0 个元素赋值为 0 即可。
2) 只能给元素逐个赋值,不能给数组整体赋值。例如给 10 个元素全部赋值为 1,只能写作:
int a[10] = {1, 1, 1, 1, 1, 1, 1, 1, 1, 1};
而不能写作:
int a[10] = 1;
3) 如给全部元素赋值,那么在定义数组时可以不给出数组长度。例如:
int a[] = {1, 2, 3, 4, 5};
等价于
int a[5] = {1, 2, 3, 4, 5};
最后,我们借助数组来输出一个 4×4 的矩阵:
1. #include <stdio.h>
2. int main()
3. {
4. int a[4] = {20, 345, 700, 22};
5. int b[4] = {56720, 9999, 20098, 2};
6. int c[4] = {233, 205, 1, 6666};
7. int d[4] = {34, 0, 23, 23006783};
9. printf("%-9d %-9d %-9d %-9d\n", a[0], a[1], a[2], a[3]);
10. printf("%-9d %-9d %-9d %-9d\n", b[0], b[1], b[2], b[3]);
11. printf("%-9d %-9d %-9d %-9d\n", c[0], c[1], c[2], c[3]);
12. printf("%-9d %-9d %-9d %-9d\n", d[0], d[1], d[2], d[3]);
14. return 0;
15. }
6.4.3 修改
6.4.4 转化
注意:原生库函数中是没有类似于强制把整形数组转换成字符串的函数的,原因见链接
7. 函数
7.1 简介
7.1.1 引例
从表面上看,函数在使用时必须带上括号,有必要的话还要传递参数,函数的执行结果也可以赋值给其它变量。例如,strcmp() 是一个用来比较字符串大小的函数,它的用法如下:
1. #include <stdio.h>
2. #include <string.h>
3. int main(){
4. char str1[] = "http://c.biancheng.net";
5. char str2[] = "http://www.baidu.com";
6. //比较两个字符串大小
7. int result = strcmp(str1, str2);
8. printf("str1 - str2 = %d\n", result);
10. return 0;
11. }
str1 和 str2 是传递给 strcmp() 的参数,strcmp() 的处理结果赋值给了变量 result。
我们不妨设想一下,如果没有 strcmp() 函数,要想比较两个字符串的大小该怎么写呢?请看下面的代码:
1. #include <stdio.h>
2. #include <string.h>
3. int main(){
4. char str1[] = "http://c.biancheng.net";
5. char str2[] = "http://www.baidu.com";
6. int result, i;
7. //比较两个字符串大小
8. for(i=0; (result = str1[i] - str2[i]) == 0; i++){
9. if(str1[i] == '\0' || str2[i] == '\0'){
10. break;
11. }
12. }
14. printf("str1 - str2 = %d\n", result);
15. return 0;
16. }
比较字符串大小是常用的功能,一个程序可能会用到很多次,如果每次都写这样一段重复的代码,不但费时费力、容易出错,而且交给别人时也很麻烦,所以C语言提供了一个功能,允许我们将常用的代码以固定的格式封装(包装)成一个独立的模块,只要知道这个模块的名字就可以重复使用它,这个模块就叫做函数(Function)。
函数的本质是一段可以重复使用的代码,这段代码被提前编写好了,放到了指定的文件中,使用时直接调取即可。下面我们就来演示一下如何封装 strcmp() 这个函数。
1. #include <stdio.h>
3. //将比较字符串大小的代码封装成函数,并命名为strcmp_alias
4. int strcmp_alias(char *s1, char *s2){
5. int i, result;
6. for(i=0; (result = s1[i] - s2[i]) == 0; i++){
7. if(s1[i] == '\0' || s2[i] == '\0'){
8. break;
9. }
10. }
12. return result;
13. }
15. int main(){
16. char str1[] = "http://c.biancheng.net";
17. char str2[] = "http://www.baidu.com";
18. char str3[] = "http://data.biancheng.net";
19. //重复使用strcmp_alias()函数
20. int result_1_2 = strcmp_alias(str1, str2);
21. int result_1_3 = strcmp_alias(str1, str3);
22. printf("str1 - str2 = %d\n", result_1_2);
23. printf("str1 - str3 = %d\n", result_1_3);
25. return 0;
26. }
为了避免与原有的 strcmp 产生命名冲突,我将新函数命名为 strcmp_alias。
这是我们自己编写的函数,放在了当前源文件中(函数封装和函数使用在同一个源文件中),所以不需要引入头文件;而C语言自带的 strcmp() 放在了其它的源文件中(函数封装和函数使用不在同一个源文件中),并在 string.h 头文件中告诉我们如何使用,所以我们必须引入 string.h 头文件。
我们自己编写的 strcmp_alias() 和原有的 strcmp() 在功能和格式上都是一样的,只是存放的位置不同,所以一个需要引入头文件,一个不需要引入。
本章我们重点讲解的内容就是如何将一段代码封装成函数,以及封装以后如何使用。
7.1.2 参数
函数的一个明显特征就是使用时带括号( ),有必要的话,括号中还要包含数据或变量,称为参数(Parameter)。参数是函数需要处理的数据,例如:
strlen(str1)用来计算字符串的长度,str1就是参数。puts("C语言中文网")用来输出字符串,"C语言中文网"就是参数。
7.1.3 返回值
既然函数可以处理数据,那就有必要将处理结果告诉我们,所以很多函数都有返回值(Return Value)。所谓返回值,就是函数的执行结果。例如:
char str1[] = "C Language";
int len = strlen(str1);
strlen() 的处理结果是字符串 str1 的长度,是一个整数,我们通过 len 变量来接收。
函数返回值有固定的数据类型(int、char、float等),用来接收返回值的变量类型要一致。
7.1.4 种类
7.1.4.1 库函数
C语言在发布时已经为我们封装好了很多函数,它们被分门别类地放到了不同的头文件中(暂时先这样认为),使用函数时引入对应的头文件即可。这些函数都是专家编写的,执行效率极高,并且考虑到了各种边界情况,各位读者请放心使用。
C语言自带的函数称为库函数(Library Function)。库(Library)是编程中的一个基本概念,可以简单地认为它是一系列函数的集合,在磁盘上往往是一个文件夹。C语言自带的库称为标准库(Standard Library),其他公司或个人开发的库称为第三方库(Third-Party Library)。
7.1.4.2 自定义函数
除了库函数,我们还可以编写自己的函数,拓展程序的功能。自己编写的函数称为自定义函数。自定义函数和库函数在编写和使用方式上完全相同,只是由不同的机构来编写。
与数学中的函数关联
美国人将函数称为“Function”。Function 除了有“函数”的意思,还有“功能”的意思,中国人将 Function 译为“函数”而不是“功能”,是因为C语言中的函数和数学中的函数在使用形式上有些类似,例如:
- C语言中有 length = strlen(str)
- 数学中有 y = f(x)
你看它们是何其相似,都是通过一定的操作或规则,由一份数据得到另一份数据。
不过从本质上看,将 Function 理解为“功能”或许更恰当,C语言中的函数往往是独立地实现了某项功能。一个程序由多个函数组成,可以理解为「一个程序由多个小的功能叠加而成」。
本教程重在实践,不咬文嚼字,不死扣概念,大家理解即可,不必在此深究。
7.2 函数定义
函数是一段可以重复使用的代码,用来独立地完成某个功能,它可以接收用户传递的数据,也可以不接收。接收用户数据的函数在定义时要指明参数,不接收用户数据的不需要指明,根据这一点可以将函数分为有参函数和无参函数。
将代码段封装成函数的过程叫做函数定义。
7.2.1 无参函数的定义
如果函数不接收用户传递的数据,那么定义时可以不带参数。如下所示:
dataType functionName(){
//body
}
- dataType 是返回值类型,它可以是C语言中的任意数据类型,例如 int、float、char 等。
- functionName 是函数名,它是标识符的一种,命名规则和标识符相同。函数名后面的括号
( )不能少。
- body 是函数体,它是函数需要执行的代码,是函数的主体部分。即使只有一个语句,函数体也要由
{ }包围。
- 如果有返回值,在函数体中使用 return 语句返回。return 出来的数据的类型要和 dataType 一样。
例如,定义一个函数,计算从 1 加到 100 的结果:
1. int sum(){
2. int i, sum=0;
3. [for](https://c.biancheng.net/view/1811.html)(i=1; i<=100; i++){
4. sum+=i;
5. }
6. return sum;
7. }
累加结果保存在变量sum中,最后通过return语句返回。sum 是 int 型,返回值也是 int 类型,它们一一对应。
return是C语言中的一个关键字,只能用在函数中,用来返回处理结果。
将上面的代码补充完整:
1. #include <stdio.h>
3. int sum(){
4. int i, sum=0;
5. for(i=1; i<=100; i++){
6. sum+=i;
7. }
8. return sum;
9. }
11. int main(){
12. int a = sum();
13. printf("The sum is %d\n", a);
14. return 0;
15. }
运行结果:
The sum is 5050
函数不能嵌套定义,main 也是一个函数定义,所以要将 sum 放在 main 外面。函数必须先定义后使用,所以 sum 要放在 main 前面。
注意:main 是函数定义,不是函数调用。当可执行文件加载到内存后,系统从 main 函数开始执行,也就是说,系统会调用我们定义的 main 函数。
7.2.2 无返回值函数定义
有的函数不需要返回值,或者返回值类型不确定(很少见),那么可以用 void 表示,例如:
1. void hello(){
2. printf ("Hello,world \n");
3. //没有返回值就不需要 return 语句
4. }
void是C语言中的一个关键字,表示“空类型”或“无类型”,绝大部分情况下也就意味着没有 return 语句。
7.2.3 有参函数的定义
如果函数需要接收用户传递的数据,那么定义时就要带上参数。如下所示:
dataType functionName( dataType1 param1, dataType2 param2 ... ){
//body
}
dataType1 param1, dataType2 param2 ...是参数列表。函数可以只有一个参数,也可以有多个,多个参数之间由,分隔。参数本质上也是变量,定义时要指明类型和名称。与无参函数的定义相比,有参函数的定义仅仅是多了一个参数列表。
数据通过参数传递到函数内部进行处理,处理完成以后再通过返回值告知函数外部。
更改上面的例子,计算从 m 加到 n 的结果:
1. int sum(int m, int n){
2. int i, sum=0;
3. for(i=m; i<=n; i++){
4. sum+=i;
5. }
6. return sum;
7. }
参数列表中给出的参数可以在函数体中使用,使用方式和普通变量一样。
调用 sum() 函数时,需要给它传递两份数据,一份传递给 m,一份传递给 n。你可以直接传递整数,例如:
int result = sum(1, 100); //1传递给m,100传递给n
也可以传递变量:
int begin = 4;
int end = 86;
int result = sum(begin, end); //begin传递给m,end传递给n
也可以整数和变量一起传递:
int num = 33;
int result = sum(num, 80); //num传递给m,80传递给n
函数定义时给出的参数称为形式参数,简称形参;函数调用时给出的参数(也就是传递的数据)称为实际参数,简称实参。函数调用时,将实参的值传递给形参,相当于一次赋值操作。
原则上讲,实参的类型和数目要与形参保持一致。如果能够进行自动类型转换,或者进行了强制类型转换,那么实参类型也可以不同于形参类型,例如将 int 类型的实参传递给 float 类型的形参就会发生自动类型转换。
将上面的代码补充完整:
1. #include <stdio.h>
3. int sum(int m, int n){
4. int i, sum=0;
5. for(i=m; i<=n; i++){
6. sum+=i;
7. }
8. return sum;
9. }
11. int main(){
12. int begin = 5, end = 86;
13. int result = sum(begin, end);
14. printf("The sum from %d to %d is %d\n", begin, end, result);
15. return 0;
16. }
运行结果:
The sum from 5 to 86 is 3731
定义 sum() 时,参数 m、n 的值都是未知的;调用 sum() 时,将 begin、end 的值分别传递给 m、n,这和给变量赋值的过程是一样的,它等价于:
m = begin;
n = end;
7.2.4 嵌套定义非法
强调一点,C语言不允许函数嵌套定义;也就是说,不能在一个函数中定义另外一个函数,必须在所有函数之外定义另外一个函数。main() 也是一个函数定义,也不能在 main() 函数内部定义新函数。
下面的例子是错误的:
1. #include <stdio.h>
3. void func1(){
4. printf("http://c.biancheng.net");
6. void func2(){
7. printf("C语言小白变怪兽");
8. }
9. }
11. int main(){
12. func1();
13. return 0;
14. }
有些初学者认为,在 func1() 内部定义 func2(),那么调用 func1() 时也就调用了 func2(),这是错误的。
正确的写法应该是这样的:
1. #include <stdio.h>
3. void func2(){
4. printf("C语言小白变怪兽");
5. }
7. void func1(){
8. printf("http://c.biancheng.net");
9. func2();
10. }
12. int main(){
13. func1();
14. return 0;
15. }
func1()、func2()、main() 三个函数是平行的,谁也不能位于谁的内部,要想达到「调用 func1() 时也调用 func2()」的目的,必须将 func2() 定义在 func1() 外面,并在 func1() 内部调用 func2()。
7.3 形参和实参
如果把函数比喻成一台机器,那么参数就是原材料,返回值就是最终产品;从一定程度上讲,函数的作用就是根据不同的参数产生不同的返回值。
这一节我们先来讲解C语言函数的参数,下一节再讲解C语言函数的返回值。
C语言函数的参数会出现在两个地方,分别是函数定义处和函数调用处,这两个地方的参数是有区别的。
7.3.1 形参
在函数定义中出现的参数可以看做是一个占位符,它没有数据,只能等到函数被调用时接收传递进来的数据,所以称为形式参数,简称形参。
7.3.2 实参
函数被调用时给出的参数包含了实实在在的数据,会被函数内部的代码使用,所以称为实际参数,简称实参。
形参和实参的功能是传递数据,发生函数调用时,实参的值会传递给形参。
7.3.3 区分
1) 形参变量只有在函数被调用时才会分配内存,调用结束后,立刻释放内存,所以形参变量只有在函数内部有效,不能在函数外部使用。
2) 实参可以是常量、变量、表达式、函数等,无论实参是何种类型的数据,在进行函数调用时,它们都必须有确定的值,以便把这些值传送给形参,所以应该提前用赋值、输入等办法使实参获得确定值。
3) 实参和形参在数量上、类型上、顺序上必须严格一致,否则会发生“类型不匹配”的错误。当然,如果能够进行自动类型转换,或者进行了强制类型转换,那么实参类型也可以不同于形参类型。
4) 函数调用中发生的数据传递是单向的,只能把实参的值传递给形参,而不能把形参的值反向地传递给实参;换句话说,一旦完成数据的传递,实参和形参就再也没有瓜葛了,所以,在函数调用过程中,形参的值发生改变并不会影响实参(除非传递的是实参数的内存地址,改变了实参变量的地址指向)。
请看下面的例子:
1. #include <stdio.h>
3. //计算从m加到n的值
4. int sum(int m, int n) {
5. int i;
6. for(i = m+1; i <= n; ++i)
7. {
8. m += i;
9. }
10. return m;
11. }
12. int main() {
13. int a, b, total;
14. printf("Input two numbers: ");
15. scanf("%d %d", &a, &b);
16. total = sum(a, b);
17. printf("a=%d, b=%d\n", a, b);
18. printf("total=%d\n", total);
19. return 0;
20. }
运行结果:
Input two numbers: 1 100↙
a=1, b=100
total=5050
在这段代码中,函数定义处的 m、n 是形参,函数调用处的 a、b 是实参。通过 scanf() 可以读取用户输入的数据,并赋值给 a、b,在调用 sum() 函数时,这份数据会传递给形参 m、n。
从运行情况看,输入 a 值为 1,即实参 a 的值为 1,把这个值传递给函数 sum() 后,形参 m 的初始值也为 1,在函数执行过程中,形参 m 的值变为 5050。函数运行结束后,输出实参 a 的值仍为 1,可见实参的值不会随形参的变化而变化。
以上调用 sum() 时是将变量作为函数实参,除此以外,你也可以将常量、表达式、函数返回值作为实参,如下所示:
1. total = sum(10, 98); //将常量作为实参
2. total = sum(a+10, b-3); //将表达式作为实参
3. total = sum( pow(2,2), abs(-100) ); //将函数返回值作为实参
5) 形参和实参虽然可以同名,但它们之间是相互独立的,互不影响,因为实参在函数外部有效,而形参在函数内部有效。
更改上面的代码,让实参和形参同名:
1. #include <stdio.h>
3. //计算从m加到n的值
4. int sum(int m, int n) {
5. int i;
6. for (i = m + 1; i <= n; ++i) {
7. m += i;
8. }
9. return m;
10. }
12. int main() {
13. int m, n, total;
14. printf("Input two numbers: ");
15. scanf("%d %d", &m, &n);
16. total = sum(m, n);
17. printf("m=%d, n=%d\n", m, n);
18. printf("total=%d\n", total);
20. return 0;
21. }
运行结果:
Input two numbers: 1 100
m=1, n=100
total=5050
调用 sum() 函数后,函数内部的形参 m 的值已经发生了变化,而函数外部的实参 m 的值依然保持不变,可见它们是相互独立的两个变量,除了传递参数的一瞬间,其它时候是没有瓜葛的。
8. 结构体
9. 指针
9.1 简介
计算机中所有的数据都必须放在内存中,不同类型的数据占用的字节数不一样,例如 int 占用 4 个字节,char 占用 1 个字节。为了正确地访问这些数据,必须为每个字节都编上号码,就像门牌号、身份证号一样,每个字节的编号是唯一的,根据编号可以准确地找到某个字节。
下图是 4G 内存中每个字节的编号(以十六进制表示):

我们将内存中字节的编号称为地址(Address)或指针(Pointer)。地址从 0 开始依次增加,对于 32 位环境,程序能够使用的内存为 4GB,最小的地址为 0,最大的地址为 0XFFFFFFFF。
下面的代码演示了如何输出一个地址:
1. #include <stdio.h>
3. int main(){
4. int a = 100;
5. char str[20] = "c.biancheng.net";
6. printf("%#X, %#X\n", &a, str);
7. return 0;
8. }
运行结果:
0X28FF3C, 0X28FF10
%#X表示以十六进制形式输出,并附带前缀0X。a 是一个变量,用来存放整数,需要在前面加&来获得它的地址;str 本身就表示字符串的首地址,不需要加&。
C语言中有一个控制符%p,专门用来以十六进制形式输出地址,不过 %p 的输出格式并不统一,有的编译器带0x前缀,有的不带,所以此处我们并没有采用。
为什么会产生这种现象?从计算机的角度来讲,一切编程操作都是地址操作
C语言用变量来存储数据,用函数来定义一段可以重复使用的代码,它们最终都要放到内存中才能供 CPU 使用。
数据和代码都以二进制的形式存储在内存中,计算机无法从格式上区分某块内存到底存储的是数据还是代码。当程序被加载到内存后,操作系统会给不同的内存块指定不同的权限,拥有读取和执行权限的内存块就是代码,而拥有读取和写入权限(也可能只有读取权限)的内存块就是数据。
CPU 只能通过地址来取得内存中的代码和数据,程序在执行过程中会告知 CPU 要执行的代码以及要读写的数据的地址。如果程序不小心出错,或者开发者有意为之,在 CPU 要写入数据时给它一个代码区域的地址,就会发生内存访问错误。这种内存访问错误会被硬件和操作系统拦截,强制程序崩溃,程序员没有挽救的机会。
CPU 访问内存时需要的是地址,而不是变量名和函数名!变量名和函数名只是地址的一种助记符,当源文件被编译和链接成可执行程序后,它们都会被替换成地址。编译和链接过程的一项重要任务就是找到这些名称所对应的地址。
假设变量 a、b、c 在内存中的地址分别是 0X1000、0X2000、0X3000,那么加法运算c = a + b;将会被编译步骤转换成类似下面的形式(汇编分析的角度):
0X3000 = (0X1000) + (0X2000);
( )表示取值操作,整个表达式的意思是,取出地址 0X1000 和 0X2000 上的值,将它们相加,把相加的结果赋值给地址为 0X3000 的内存
变量名和函数名为我们提供了方便,让我们在编写代码的过程中可以使用易于阅读和理解的英文字符串,不用直接面对二进制地址,那场景简直让人崩溃。
需要注意的是,虽然变量名、函数名、字符串名和数组名在本质上是一样的,它们都是地址的助记符,但在编写代码的过程中,我们认为变量名表示的是数据本身,而函数名、字符串名和数组名表示的是代码块或数据块的首地址。
9.2 概念
9.3 特性
9.4 操作
数据在内存中的地址也称为指针,如果一个变量存储了一份数据的指针,我们就称它为指针变量。
在C语言中,允许用一个变量来存放指针,这种变量称为指针变量。指针变量的值就是某份数据的地址,这样的一份数据可以是数组、字符串、函数,也可以是另外的一个普通变量或指针变量。
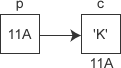
现在假设有一个 char 类型的变量 c,它存储了字符 'K'(ASCII码为十进制数 75),并占用了地址为 0X11A 的内存(地址通常用十六进制表示)。另外有一个指针变量 p,它的值为 0X11A,正好等于变量 c 的地址,这种情况我们就称 p 指向了 c,或者说 p 是指向变量 c 的指针。
9.2.1 定义
定义指针变量与定义普通变量非常类似,不过要在变量名前面加星号*,格式为:
datatype *name;
或者
datatype *name = value;
*表示这是一个指针变量,datatype表示该指针变量所指向的数据的类型 。例如:
- int *p1;
p1 是一个指向 int 类型数据的指针变量,至于 p1 究竟指向哪一份数据,应该由赋予它的值决定。再如:
1. int a = 100;
2. int *p_a = &a;
在定义指针变量 p_a 的同时对它进行初始化,并将变量 a 的地址赋予它,此时 p_a 就指向了 a。值得注意的是,p_a 需要的一个地址,a 前面必须要加取地址符&,否则是不对的。
和普通变量一样,指针变量也可以被多次写入,只要你想,随时都能够改变指针变量的值,请看下面的代码:
1. //定义普通变量
2. float a = 99.5, b = 10.6;
3. char c = '@', d = '#';
4. //定义指针变量
5. float *p1 = &a;
6. char *p2 = &c;
7. //修改指针变量的值
8. p1 = &b;
9. p2 = &d;
*是一个特殊符号,表明一个变量是指针变量,定义 p1、p2 时必须带*。而给 p1、p2 赋值时,因为已经知道了它是一个指针变量,就没必要多此一举再带上*,后边可以像使用普通变量一样来使用指针变量。也就是说,定义指针变量时必须带*,给指针变量赋值时不能带*。
假设变量 a、b、c、d 的地址分别为 0X1000、0X1004、0X2000、0X2004,下面的示意图很好地反映了 p1、p2 指向的变化:
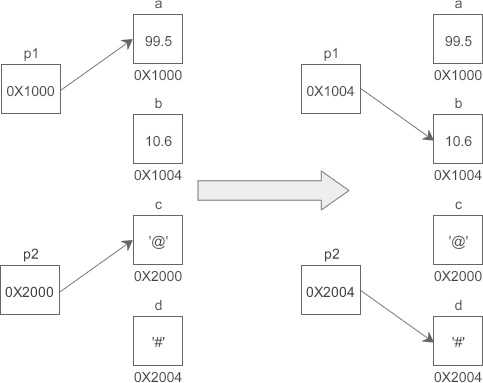
需要强调的是,p1、p2 的类型分别是float*和char*,而不是float和char,它们是完全不同的数据类型,读者要引起注意。
指针变量也可以连续定义,例如:
1. int *a, *b, *c; //a、b、c 的类型都是 int*
注意每个变量前面都要带*。如果写成下面的形式,那么只有 a 是指针变量,b、c 都是类型为 int 的普通变量:
1. int *a, b, c;
9.2.3 访问
指针变量存储了数据的地址,通过指针变量能够获得该地址上的数据,格式为:
*pointer;
这里的*称为指针运算符,用来取得某个地址上的数据,请看下面的例子:
1. #include <stdio.h>
3. int main(){
4. int a = 15;
5. int *p = &a;
6. [printf](https://c.biancheng.net/view/ublxqif.html)("%d, %d\n", a, *p); //两种方式都可以输出a的值
7. return 0;
8. }
运行结果:
15, 15
假设 a 的地址是 0X1000,p 指向 a 后,p 本身的值也会变为 0X1000,p 表示获取地址 0X1000 上的数据,也即变量 a 的值。从运行结果看,p 和 a 是等价的。
上节我们说过,CPU 读写数据必须要知道数据在内存中的地址,普通变量和指针变量都是地址的助记符,虽然通过 *p 和 a 获取到的数据一样,但它们的运行过程稍有不同:a 只需要一次运算就能够取得数据,而 *p 要经过两次运算,多了一层“间接”。
假设变量 a、p 的地址分别为 0X1000、0XF0A0,它们的指向关系如下图所示:
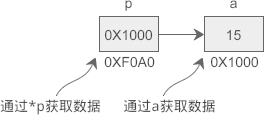
程序被编译和链接后,a、p 被替换成相应的地址。使用 *p 的话,要先通过地址 0XF0A0 取得变量 p 本身的值,这个值是变量 a 的地址,然后再通过这个值取得变量 a 的数据,前后共有两次运算;而使用 a 的话,可以通过地址 0X1000 直接取得它的数据,只需要一步运算。
也就是说,使用指针是间接获取数据,使用变量名是直接获取数据,前者比后者的代价要高。
指针除了可以获取内存上的数据,也可以修改内存上的数据,例如:
1. #include <stdio.h>
3. int main(){
4. int a = 15, b = 99, c = 222;
5. int *p = &a; //定义指针变量
6. *p = b; //通过指针变量修改内存上的数据
7. c = *p; //通过指针变量获取内存上的数据
8. printf("%d, %d, %d, %d\n", a, b, c, *p);
9. return 0;
10. }
运行结果:
99, 99, 99, 99
*p 代表的是 a 中的数据,它等价于 a,可以将另外的一份数据赋值给它,也可以将它赋值给另外的一个变量。
*在不同的场景下有不同的作用:*可以用在指针变量的定义中,表明这是一个指针变量,以和普通变量区分开;使用指针变量时在前面加*表示获取指针指向的数据,或者说表示的是指针指向的数据本身。
也就是说,定义指针变量时的*和使用指针变量时的*意义完全不同。以下面的语句为例:
1. int *p = &a;
2. *p = 100;
第1行代码中*用来指明 p 是一个指针变量,第2行代码中*用来获取指针指向的数据。
需要注意的是,给指针变量本身赋值时不能加*。修改上面的语句:
1. int *p;
2. p = &a;
3. *p = 100;
第2行代码中的 p 前面就不能加*。
指针变量也可以出现在普通变量能出现的任何表达式中,例如:
1. int x, y, *px = &x, *py = &y;
2. y = *px + 5; //表示把x的内容加5并赋给y,*px+5相当于(*px)+5
3. y = ++*px; //px的内容加上1之后赋给y,++*px相当于++(*px)
4. y = *px++; //相当于y=*(px++)
5. py = px; //把一个指针的值赋给另一个指针
【示例】通过指针交换两个变量的值。
1. #include <stdio.h>
3. int main(){
4. int a = 100, b = 999, temp;
5. int *pa = &a, *pb = &b;
6. printf("a=%d, b=%d\n", a, b);
7. /*****开始交换*****/
8. temp = *pa; //将a的值先保存起来
9. *pa = *pb; //将b的值交给a
10. *pb = temp; //再将保存起来的a的值交给b
11. /*****结束交换*****/
12. printf("a=%d, b=%d\n", a, b);
13. return 0;
14. }
运行结果:
a=100, b=999
a=999, b=100
从运行结果可以看出,a、b 的值已经发生了交换。需要注意的是临时变量 temp,它的作用特别重要,因为执行*pa = *pb;语句后 a 的值会被 b 的值覆盖,如果不先将 a 的值保存起来以后就找不到了。
9.4 总结
9.4.1 关于 * 和 &
假设有一个 int 类型的变量 a,pa 是指向它的指针,那么*&a和&*pa分别是什么意思呢?
*&a可以理解为*(&a),&a表示取变量 a 的地址(等价于 pa),*(&a)表示取这个地址上的数据(等价于 *pa),绕来绕去,又回到了原点,*&a仍然等价于 a。
&*pa可以理解为&(*pa),*pa表示取得 pa 指向的数据(等价于 a),&(*pa)表示数据的地址(等价于 &a),所以&*pa等价于 pa。
9.4.2 对星号*的总结
在我们目前所学到的语法中,星号*主要有三种用途:
- 表示乘法,例如
int a = 3, b = 5, c; c = a * b;,这是最容易理解的。
- 表示定义一个指针变量,以和普通变量区分开,例如
int a = 100; int *p = &a;。
- 表示获取指针指向的数据,是一种间接操作,例如
int a, b, *p = &a; *p = 100; b = *p;。
10. IO
10.1 文件操作
10.2 媒体流
10.3 网络流
11. 预处理
12. 调试
13. 补充